


|
29 October 2023
AWK and NS2 Tracefile | NS2 Tutorial 3

Installation of NS2 in Ubuntu 22.04 | NS2 Tutorial 2
NS-2.35 installation in Ubuntu 22.04
This post shows how to install ns-2.35 in Ubuntu 22.04 Operating System
Since ns-2.35 is too old, it needs the following packages
gcc-4.8
g++-4.8
gawk
and some more libraries
Follow the video for more instructions
So, here are the steps to install this software:
To download and extract the ns2 software
Download the software from the following link
Extract it to home folder and in my case its /home/pradeepkumar (I recommend to install it under your home folder)
$ tar zxvf ns-allinone-2.35.tar.gz
or Right click over the file and click extract here and select the home folder.
$ sudo apt update
$ sudo apt install build-essential autoconf automake libxmu-dev gawk
To install gcc-4.8 and g++-4.8
$ sudo gedit /etc/apt/sources.list
make an entry in the above file
Since, it's ubuntu 22.04, you may get an error called GPG Error with a code like this "3B4FE6ACC0B21F32"
In case you get the GPG error, include the following command
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 3B4FE6ACC0B21F32
$ sudo apt update
$ sudo apt install gcc-4.8 g++-4.8
Make the changes in the following files
@CC@ to be replaced with gcc-4.8
@CPP@ to be replaced with g++-4.8
ns-allinone-2.35/Makefile.in
/home/pradeepkumar/ns-allinone-2.35/otcl-1.14/Makefile.in
nam-1.15/Makefile.in
xgraph-12.2/Makefile.in
In all the above places, change @CC@ to gcc-4.8
and @CPP@ @CXX@ to g++-4.8
Open the file
ns-2.35/linkstate/ls.h
in line number 137, change the line erase to this-erase
Once the installation is over, Set the PATH and LD_LIBRARY_PATH information in the file located at
/home/pradeepkumar/.bashrc
export PATH=$PATH:/home/pradeepkumar/ns-allinone-2.35/bin:/home/pradeepkumar/ns-allinone-2.35/tcl8.5.10/unix:/home/pradeepkumar/ns-allinone-2.35/tk8.5.10/unix
export LD_LIBRARY_PATH=/home/pradeepkumar/ns-allinone-2.35/otcl-1.14:/home/pradeepkumar/ns-allinone-2.35/lib
You can change /home/pradeepkumar to your home folder name.
$ns
$nam
$ xgraph
1 2
3 4
5 6
6 7
8 9
10 11
and press Control D (You can get a good graph) and that's it...
For video lectures of this kind, subscribe to my Channel https://www.youtube.com/tspradeepkumar
Introduction to Network Simulator 2 | NS2 Tutorial 1
|
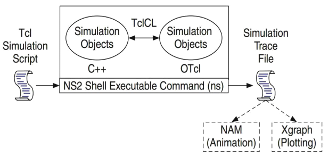 The basic
The basicAbout Me

Featured Post
5G Network Simulation in NS3 using mmWave | NS3 Tutorial 2024
5G Network Simulation in NS3 Using mmWave This post shows the installation of ns3mmwave in Ubuntu 24.04 and simulates 5G networks in ns3. In...

Most Popular
-
How to create a new agent in NS2. You can use any version of the Simulator. The following codes will make you to understand the writing of a...
-
 This post tells you how to install TinyOS installation in Ubuntu 12.04 (I used this old OS as the tinyos 2.0.2 is released earlier and has ...
This post tells you how to install TinyOS installation in Ubuntu 12.04 (I used this old OS as the tinyos 2.0.2 is released earlier and has ... -
How to Create Ubuntu 24.04 Bootable USB Using Rufus [Step-by-Step Guide] Are you planning to install or try Ubuntu 24.04 LTS ? The easi...

Popular Posts
-
How to create a new agent in NS2. You can use any version of the Simulator. The following codes will make you to understand the writing of a...
-
This post tells you how to install TinyOS installation in Ubuntu 12.04 (I used this old OS as the tinyos 2.0.2 is released earlier and has ...
-
How to Create Ubuntu 24.04 Bootable USB Using Rufus [Step-by-Step Guide] Are you planning to install or try Ubuntu 24.04 LTS ? The easi...


